

本コラムでは、製造業が今後10年間で直面するであろう、技術革新を主軸とした抜本的な変革について考察しています。
IoT、AI、ロボット工学、3Dプリンティングなどの先進技術が融合することで、「スマートファクトリー」の実現が加速し、ものづくりのあり方が劇的に変化します。具体的には、生産ラインの自律化と最適化、データ駆動による品質管理の向上、個別カスタマイズ生産の普及、そしてサプライチェーン全体の効率化といった変化を予測しています。これらの技術は、生産性向上やコスト削減に寄与する一方で、新たなスキルセットの需要や、サイバーセキュリティのリスクといった課題も生じさせると指摘しています。これからのものづくりは、単に製品を作るだけでなく、デジタル技術を駆使して新たな価値を創造するサービス化への移行が求められ、企業には変化への迅速な適応と、継続的なイノベーションへの投資が不可欠であると示唆しています。
コンピューターの課題と不得意分野
コンピューターの得意分野と不得意分野
コンピューターの飛躍的な進歩により、今私たちが手にしているスマートフォンは、20年前のスーパーコンピューターと同じ能力を持っています。動画をストリーミング再生したり、リアルタイムで現在地を表示したり、写真の画像を手直しするなど、以前のパソコンでは想像もできなかったことができるようになりました。
それでも依然として、コンピューターが得意なこと、不得意なことはあります。
【得意なこと】
- 一定のルールやアルゴリズムがあること
- 入力に対し、答えが定まっていること
【苦手なこと】
- ルールやアルゴリズムが常に変わるもの
- 入力に対し、出力が定まらないもの
以前は扱えるデータ量やプロセッサの演算能力に制約があったため、たとえルールやアルゴリズムがあっても実現できないことがありました。それがコンピューターの演算速度の向上やメモリ容量の拡大、通信速度の向上により、実現できるようになりました。それでもコンピューターが苦手なことがあります。
コンピューターが苦手なことは、相変わらず苦手
それは、パターン認識など、あいまいなものを識別することです。
人間はスーパーの陳列棚にあるりんごと桃から、りんごだけをかごに入れることは、3歳児でもできます。
しかしコンピューターが、他の果物もある中からりんごの特徴を抽出して、識別するのは容易ではありません。様々な大きさ、色、置き方の異なるりんごと桃から、リンゴの特徴を識別しなければならないからです。

図1 この中からりんごを選ぶのは…
モラベックのパラドクス
実は人間の知能をコンピューターに置き換える際、高度な推論よりも、感覚運動スキルの方が多くの計算資源を必要とします。これは1980年代以降、人工知能 (AI)を研究する過程でわかってきて、
「モラベックのパラドクス」
と呼ばれています。
モラベックは
「コンピューターに知能テストを受けさせたり、チェッカーをプレイさせたりするよりも、
1歳児レベルの知覚と運動のスキルを与える方が遥かに難しいか、
あるいは不可能である」
と記しています。

図2 1歳児にも負けるコンピューター
言語学者で認知心理学者のスティーブン・ピンカーは、
「35年に及ぶAI研究で判明したのは
『難しい問題は容易』で『容易な問題が難しい』
ということである。
我々が当然なものとみなしている4歳児の身体的能力、すなわち顔を識別したり、鉛筆を持ち上げたり、部屋を歩き回ったり、質問に答えたりといったこと(をAIで実現すること)は、かつてないほど難しい工学上の問題を解決することになる。
(中略)
新世代の知的機械が登場したとき、職を失う危険があるのは証券アナリストや石油化学技師や仮釈放決定委員会のメンバーなどになるだろう。庭師や受付係や料理人といった職業は当分の間安泰である。」
と、述べています。

図3 証券アナリスト

図4 料理人

図5 植木職人
マービン・ミンスキーは、
最も解明が難しい人間のスキルは「無意識」だ
としています。
「一般に我々は、我々の精神が最も得意なことについて最も気付いていない。」
「我々は完璧に働く複雑な過程よりも、うまく機能しない簡単な過程の方をよく知っている」
としています。
ロボット開発の大きな課題 SLAM問題
SLAM問題(Simultaneous Location and Mapping)とは、
コンピューターにとって自己位置推定と周囲環境のマッピングを同時に行うことが容易でないことです。
ロボットが目的地まで安全かつ正確に走行するためには、
周囲の地図を生成するのと同時に、その地図上で自己位置を推定する必要があります。
この地図生成と自己位置を同時に行う問題をSLAM問題と呼び、ロボット分野の基礎的な問題の一つです。
SLAM問題の応用として、自律走行車や環境再構築などがあります。これを実現するためには、物体識別、分類、動物体追跡、パターン認識と機械学習、フィルタリング、全体最適化、記憶と検索、圧縮と復元などの個々の技術を高め、それを高度に融合する必要があります。
このSLAM問題は、
「内界センサーだけでなく、外界センサーの情報も利用して自己位置推定を行う」
ことです。
人間が移動するときは、以下のようにして位置を把握します。
- 視覚情報:目から得た色情報と、二つの眼の情報の関連性から導き出した幾何学的情報(物や環境の色と形)
- 慣性力情報:三半規管から、回転の加速度や速度の検知(どれだけ自分が回転しているのか)
- 重力センサー:三半規管や、その他もろもろの感覚器官の情報から、自分がどのような姿勢をしているのか検知。
- 触覚センサー:人間の皮膚には、何かに触れたことや、触った物体の材質などを検知します。
- その他センサー:以上のような人間の感覚のほかに、人間には聴覚や、嗅覚、そして味覚などの感覚器が存在しています。
従来SLAM技術が確立するまでは、内界センサーのみを使用した自己位置推定がメインでした。人間でいうところの目を瞑って歩きながら、自分の歩幅とかのみで、自分の位置を推定している状態でした。
現在は、各種センサーにより外界情報の取得と、これを自己位置推定に反映することで、精度は大きく向上しました。
苦手を克服し始めたコンピューター
こうしたコンピューターの苦手なことには、翻訳、音声認識、車の運転なども含まれます。しかし、多くの方は疑問に思います。
「翻訳、音声認識、運転も
『もうできているか』『近い将来実用化される』
のではないか」
そう、今までできなかったことができるようになってきています。それがビッグデータ解析技術と機械学習です。
ビッグデータ解析技術 結果が分かれば理由はいらない
従来データ分析は、データベース(リレーショナルデータベース)の構築が不可欠でした。最初に「それぞれの項目にはどのような数値を入れるのか」といったデータの入れ物を詳細に設計します。そしてデータの関連性を分析します。
つまり事前に「こうなるであろう」という推測をして、それには「どのようなデータが必要なのか」あらかじめ決めておかなければ分析できませんでした。後からデータを追加しようとすると、データベースを大きく改造しなければならず大変な手間がかかりました。またデータを入れる入れ物の大きさにも制約があったので、データの数が多い場合は、サンプリングを行いデータの数を少なくする必要がありました。
ところがビッグデータ解析では、以下の点で従来のデータベースによる解析とは大きく異なります。
- 全てのデータを扱う(N=全部)
- 量があれば、精度は重要でない(量は質を凌駕する)
- 理由はいらない (因果関係から相関関係へ)
予め分析の仕方やデータの構成をしっかり決めてなくても、とにかくデータを集めておけば、後から様々な切り口で分析できます。分析の結果、理由は「分からないけど結果としてこうなっている」ということがわかれば、十分に役立つという考え方です。
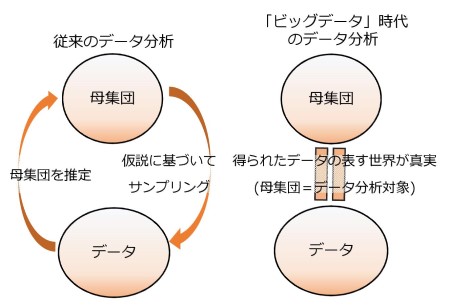
図6 従来データ解析とビッグデータ
有名な事例としては、ビールと紙おむつの事例があります。
アメリカのある小売りチェーンが購買データを分析したところ、夕方紙おむつを買う顧客は同時にビールも買うことが多いことが分かりました。そこで紙おむつ売り場の横にビールを置いて売上を増やすことができました。これは従来の顧客の行動を想定した方法ではわからなかったことです。
現在では、アマゾンで商品を購入すると「この商品を買った方は、こんな商品も買っています」というリコメンデッド機能がありますが、これもビッグデータ解析の結果です。
その結果、2012年の時点で、処理が可能なデータサイズはエクサバイトのオーダーでした。例えば、ゲノミクス、気象学、複雑な物理シミュレーション、生物調査および環境調査や、インターネット検索、金融などでは、このように膨大なデータを扱う分野があります。
そのため、全世界での1人当たりの情報容量は、1980年代以降40か月ごとに倍増し、2012年の時点で1日あたり250京(2.5×1018)バイトのデータが作成されていました。そしてビッグデータの解析のために、数百台、ときには数千台のサーバ上で動く大規模な並列処理ソフトウェアが使われています。今後、IoTの進展によりセンターやカメラが増加するとためデータ量はさらに増加します。
潤沢な世界
2000年に、全世界で記録された情報の中でデジタルデータは25%でした。それが2007年には、281エクサバイト(10の18乗)のデータが記録・伝達 (このうち7%がアナログデータ)されています。
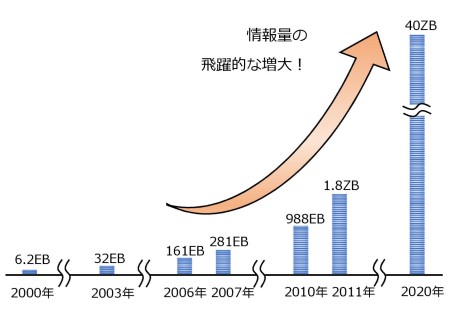
図7 データ量の増加
全てのデータを扱う(N=全部)
従来は測定できるデータも解析できるコンピューターの能力にも限りがあるため、多くの現象はサンプルを抽出して、それを解析していました。
ビッグデータでは、全てのデータ、数億個かそれ以上のデータを相関分析することで、理由は分からないけど確率の高い因果関係を見つけます。
常識にとらわれない発見で売り上げ増加 (Zの法則を打ち破ったダイドードリンコ)
小売業界では「Zの法則」といって、陳列棚、新聞広告などを見る消費者の視点は、上段左側から右へ移動し、次に下段左側へ移動して右へ移動する、つまり視点がZ字のように移動するという法則があります。従って、上段左側に売れる商品、利益が出る商品を置く事が常識でした。
ダイドードリンコは、全ての自動販売機に視点を認識するセンサーを取り付け調査しました。その結果、自動販売機の場合は、視線は下段に集まることが分かりました。そこで主力の缶コーヒーのブレンドシリーズを下段に配置したところ、売り上げは前年比1.2%増になりました。
これまでは例え分析しても「仮説」「検証」のプロセスがありませんでした。それがセンサーとビッグデータ解析により検証した結果、Zの法則が必ずしも最適でなかったことがわかったのです。
このように理論がなくても現実に即した手法を見つけることができるのが、ビッグデータ分析の強みです。

図8 売れ筋は下だった
量があれば、精度は重要でない(量は質を凌駕する)
コンピューターによる翻訳は、コンピューターができた頃から多くの研究者が取り組んできました。「将来はコンピューターにより同時通訳できる」と期待されていましたが、なかなか実現しませんでした。
機械翻訳の問題
- 1954年IBM
250の言葉のペアと6つの文法ルールを適用して、60のロシア語の文章を英語に翻訳することに成功しました。しかしルールを教えるだけでなく、膨大な例外を教えなくてはならない点が課題となって、実用になりませんでした。
- 1990年IBM 言葉の一致に統計的確率を導入
IBMのプロジェクト「キャンディード」は、カナダ議会の議事録(英語とフランス語で正確に翻訳されている)を10年分、約300万センテンスをコンピューターに記憶させ、それを元に自動翻訳の開発に取組みました。しかし満足な結果が得られずプロジェクトは中止しました。
- 圧倒的な数を背景にしたグーグル翻訳
2006年グーグルは、WEB上にある数十億の翻訳したページを解析し、自動翻訳の開発に取組みました。現在グーグル翻訳は、同時に90か国の言語に翻訳することができます。
その翻訳は正確とは言い難く、評価は人により異なります。まだ翻訳というより、なんとか意味は理解できるというレベルです。しかし世界90か国語に短時間に翻訳するのは、どんなに優れた人でもできません。
例えば、ある会社のウェブサイトを翻訳してみました。
【英語サイト】
Our aim is not only to increase ties between the three regions and share our accumulated parts machining know-how globally, but also to bring together the best multitasking machines and 5-axis machining centers, the best machining technology, and the best people to propose premium solutions for our customers.
【英文サイトのグーグル翻訳】
3つの地域の結びつきを強め、蓄積された部品加工のノウハウを世界規模で共有するだけでなく、最高のマルチタスク加工機と5軸マシニングセンタ、最高の加工技術、そして提案する最高の人々を結集させることも目的です。お客様のためのプレミアムソリューション。
【オリジナル日本語】
日本・北米・欧州の主要3拠点のつながりを高め、蓄積した部品加工のノウハウをグローバルに共有し、最高の複合加工機・5軸制御マシニングセンタ、最高の加工技術、最高のスタッフを揃えてお客様へプレミアムなソリューションを提案して参ります。
この翻訳を何とか使えると思うか、全くダメと思うかは使う人の考え方次第だと思います。ただ、これがロシア語、タイ語、アラビア語となった場合、どうでしょうか。
「シンプルなモデルと膨大なデータの組合せは、データ量がわずかで手が込んだモデルを凌駕する。」
ピーター・ノービィグ グーグルの人工知能の第一人者
八百長試合はあったのか
「ヤバい経済学」の著者 スティーブン・レビット氏は、日本の大相撲の過去11年分6万4,000番の取組を分析しました。その結果、千秋楽で勝ち越しがかかった一番では、力士が勝つ確率が25%高くなることが分かりました。
勝ち越しするかどうかは、力士にとって収入・地位に大きく影響します。もし、勝ち越しがかかった力士と、もう勝ち越しを決めている力士が千秋楽で対戦した場合、どうなるのか、それをビッグデータは示しています。
進歩を感覚的に理解できない「ムーアの法則」
このコンピューターの進歩を予見したのが「ムーアの法則」です。
「集積回路の実装密度は18カ月ごとに2倍になる」
これは、1965年にインテル共同創業者のゴードン・ムーア氏が唱えたもので、時間とともに集積回路は高密度化し、高性能化、高速化と共に低価格化します。そのスピードは、18カ月で2倍、つまり3年ごとに4倍、15年で1024倍の容量になります。
そして進化のスピードは、1965年から2017年に至るおよそ50年間、その通りになりました。
この指数関数は図のように対数目盛で表すと、直線になります。
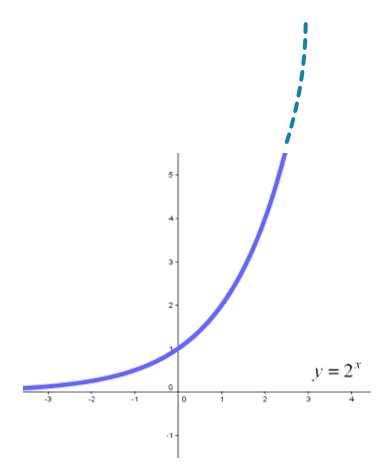
図9 指数関数
人間は、この指数関数的増加には、感覚的に対応できません。
なぜなら指数関数は、後半はものすごく急激に増加するからです。
「進歩が加速する」
という状況に感覚がついていかなくなります。
一方、材料、電池、加工方法など形ある製品の進歩は、地道な研究開発の結果です。これは指数関数的にならず、リニア(線形的)に変化します。同様に同じ電気でもアナログ回路の進歩も線形です。
つまり、電池やエンジン、その集合体の自動車などの進歩は、
リニアな地道な進歩
です。
しかし、そこに組み込まれる制御システムやコンピューターは、
予測できないような急激な進化(指数関数的)
をします。
自ら賢くなる機械学習
ねこを猫と認識
このコンピューター技術の進歩に大きく貢献しているのが、機械学習です。
機械学習とは、データから反復的に学習し、そこに潜むパターンを見つけ出すことです。 学習した結果を新たなデータにあてはめることで、パターンに従って結果を予測することができます。
つまり、入力に対して、結果が1対1で決まるようなコンピューターのシステムでは、目標値を決めておけば、結果が目標値に近づくように、自らアルゴリズムを修正します。その結果、経験すればするほど、アルゴリズムの精度が高まり、正確な答えが出るようになります。
例えば、ねこを見て、ねこであることを認識するのは、コンピューターには苦手なことでした。そこで機械学習では、大量のねこの画像を読み込ませ、ねこの特徴を抽出します。そして画像データからねこを判定する推論モデルをつくります。
次に実際に未知の画像を識別して、推論結果が間違っていれば、その結果をフィードバックして、推論モデルを修正します。その結果、認識を増やせば増やすほど推論モデルは正確になります。
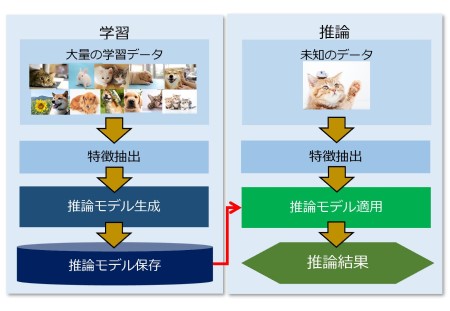
図10 機械学習の仕組み
この機械学習とビッグデータ解析技術の組み合わせにより、言語、画像、音声などのコンピューターの苦手なことができるようになってきました。
正解さえわかっていれば、大量のデータをどんどん処理して答えを調べて間違いを修正します。これを膨大な回数繰り返せば、どんどん精度が高くなります。そして高性能化した現代のコンピューターにとって大量のデータを短時間に処理することは、極めて容易なことです。
例え、その回数が数億から数兆回だったとしても…。
このビッグデータ解析と機械学習により、今まで苦手と考えられていた翻訳、音声認識ができるようになり、自動運転も将来可能になってきたのです。
人並みに働くことができるか、アマゾン・ピッキング・チャレンジ
アマゾンは、ロボット開発コンテスト「Amazon Picking Challenge(APC)」を開催し、より効率的に作業できるロボットの開発を奨励しています。いずれは自社でそのロボットを採用し、商品出荷作業のさらなる効率化を目指しています。
このAPC 2016は、2016年7月にドイツで開催され、世界中から16のチーム、そのうち日本からはAA-Team(東京大学)、C2M(中部大学、中京大学、三菱電機の混成チーム)、チームK(東京大学JSK)、PFN(Preferred Networks)の4チームが参加し、オランダのチーム・デルフトが優勝しました。
チーム・デルフトは、深層学習を採用し準備期間中に50の異なったアングルの画像のデータベースを作りました。現場に来るまでに、ロボットに学習させておいたのです。
チーム・デルフトのメンバーは、他のチームは深層学習技術を使わないと予想していました。なぜなら、深層学習にはまだ予期できない部分もあり、リスクが高かったからです。実際には、日本のPFNと接戦になりましたが、勝利しました。その結果、これからはロボットにも深層学習技術の導入が盛んになると予想されます。
【深層学習 (ディープラーニング) 】
ディープラーニングは、機械学習の1種でニューラルネットワーク技術を活用して、特徴点を階層的に学習します。この点で従来の機械学習と異なります。
これは1990年代に進められた脳、特に視覚野の研究成果によるものです。このニューラルネットワークのアルゴリズムでは、画像などの情報を第1層からより深い階層へ伝達する過程で、各層で学習が繰り返されます。ディープラーニングでは、各層での特徴点を自動で抽出することで、パターン認識精度が飛躍的に向上しました。
これはAI研究に関する大きなブレイクスルーとなり、学習方法に関する技術的な革新と言われています。2012年には、Googleの開発したグーグル・ブレインが、猫の画像を見て、猫と認識することに成功しました。
自動作曲 ヒット曲の傾向を分析して、最もヒットしやすいメロディを作成
明治大学教授の嵯峨山茂樹先生は、開発したAI作曲ソフト「オルフェウス」を使い、1950~60年代、1970年代、1980年代、1990年代、2000年代、2010年代それぞれの「平均的な曲」を作曲しました。これはNHK総合テレビ「データなび」で放送されました。
「オルフェウス」は、歌詞のイントネーションを解析し、イントネーションに合わせて自動でメロディをつくり、合成音声で出力しました。
参考記事『未来の紅白歌合戦は、人工知能が作ったヒット曲だらけになる?』
http://www.gizmodo.jp/2015/12/orpheus.html
気づかない理由 生産性革命は遅れてやってくる
こういったイノベーションは、最初に革新的な技術が誕生してから数十年後に遅れて爆発します。なぜなら画期的な技術に周辺の技術や環境が追いつかないからです。
18世紀初頭より、ニューコメンやワットにより蒸気機関が発明・改良されましたが、蒸気機関により生産性が急激に増加したのは19世紀に入ってからでした。
次の大きなイノベーションは、電力の供給と内燃機関の発明でした。電気は1890年代にはアメリカの工場に導入されましたが、それから20年間、労働生産性は大きく向上しませんでした。
なぜ20年間労働生産性は向上しなかったのか?
ポール・デービッドは、電化が始まった当初のアメリカの工場を調べた結果、工場のレイアウトに問題があることを発見しました。蒸気機関の時代の工場のレイアウトは、動力の伝達距離を最小にするため、機械を極力動力源である蒸気機関の近くに配置していました。そのため生産性の向上に限りがありました。
それから30年近く経って、当初の技師長が引退すると、工場は平屋建てになり、ものの流れに沿った現代と同様のレイアウトになり生産性は大きく向上しました。
コンピューターの世界も、最初のコンピューター「ENIAC」は1945年に登場しました。しかし、多くの企業がITに投資し生産性が飛躍的に向上したのは、インターネットが生まれた爆発的に普及した1990年代以降でした。
つまり革新的な技術が誕生しても当初はその変化は大きくなく、その後の急激な変革が予想できないのです。
パラドクスを打ち破る
このようなビッグデータ解析、機械学習、処理能力の指数関数的向上などのコンピューター技術の進歩により、今までコンピューターが苦手としていたことができるようになってきました。
その結果、一部では、モラベックのパラドクスを打ち破りつつあります。この変化が今後、ロボットにも起きるでしょう。
「ロボット市場はもうすぐ爆発的に成長すると確信している」
レミ・エルアゼイン テキサスインストルメンツ
Rethink Robotics社 バクスター
Rethink Roboticsは、掃除ロボット「ルンバ」の産みの親であるロドニー・ブルックスが新たに設立した会社です。このバクスターの最大の特徴は、作業の指示の与え方にあります。難しいプログラミングは一切不要で、バクスターの手を取って導いてやることで、作業の手順を教えることができます。
価格は、2万2000ドル(230万円程度)と安く従来の産業ロボットのようにスピードは速くありません。しかし、人と一緒に作業することができ、しかも人と違って疲れません。
以下のURLは、ロドニー・ブルックスがバクスターについて語ったTEDトークです。これからロボットがどのような方向に進むべきか興味深い意見を述べています。
「ロドニー・ブルックス なぜ、私たちはロボットに頼ることになるのか」

図11 Rethink RoboticsのSawyerとBaxterの共同ロボット
(ウィキペディアより)
アマゾン Kivaロボット
アマゾンによって2012年に買収され、アマゾンの倉庫テクノロジに組み込まれました。アマゾンは、米国内に50以上の施設を保有し、10の倉庫で計1万5000体のKivaロボットが稼働しています。
以下は、アマゾンのKivaロボットの動画です。

図12 アマゾンのKIVAロボット(ウィキペディアより)
デンソーウェーブ COBOTTA
デンソーウェーブは、コラボレーションロボット「COBOTTA(コボッタ)」を2017年に発売しました。
COBOTTAは、「人との協働」「簡単インテグレーション」「卓上アプリケーションに適した性能」をコンセプトに、人と一緒に小物部品を扱う作業を想定しています。重量は3.8kg、可搬重量は0.5kg、価格は、120~150万円です。
協働ロボットとして安全性を確保し、安全柵やライトカーテンなどは不要です。
簡単に扱えるように専用ペンダントなどではなく、実際にアームを持ちながら動作をすることで動きを覚えます。ユーザーインターフェースや軌道計画に関連するアプリケーション部分はオープン化し、ユーザーがある程度まで自由に開発できます。同社は今後「三品(食品・薬品・化粧品)業界などでの採用も目指しています。
以下は、COBOTTAのPR動画です。
ロボット開発者のためのロボット
PR2は、ロボットのソフトウェア開発者、研究者のために作られたオープンなプラットフォームのロボットです。
従来ロボット開発者は、まずハードウェアを作ってからでないとコードを実装できませんでした。
PR2を使えば、ソフトウェアの専門家がすぐにロボットに新しい機能を開発できます。
以下はPR2ロボットのPR動画です。
奥さんの代わり? 全自動洗濯物折り畳み機
セブン・ドリーマーズ・ラボラトリーズは、全自動衣類折り畳み機「/laundroid 1(ランドロイドワン)」を2019年春に発売を開始すると発表しました。
当初は出荷を2017年度中としていました。しかし、ツルツルした素材やごわごわした素材など特定の衣類に対しロボットアームがうまくつかめないことが判明したため、ロボットアームの全面改良を行いました。そのため発売が2年延期されました。価格は185万円~の想定です。
人工知能を用いた画像解析と、ロボット技術を組み合わせて、ランダムに放り込まれたシャツ、ズボン、スカート、タオルの4種を認識し、1枚ずつ畳んで収納します。折りたたみ時間は、1枚につき5〜10分です。衣類を家族別に仕分けすることもできます。
セブンドリーマーズの社長 阪根氏はメーカーで世の中にないものをつくりたいという想いで、洗濯物を全自動で折り畳める機械のプロジェクトを2005年に立上げました。2007年にはロボット工学を研究する大学と共同研究を行い、柔らかな衣類をたたむ技術を開発しました。さらにAIと画像認識技術の進歩により、ランダムに積まれた依頼を識別で切るようになりました。
しかし認識制度を95%まで高めるためには膨大な教示データが必要で25万枚もの衣類の学習が必要でした。こうして世界にまだない洗濯物を自動で折りたたむ機械が誕生しました。
追記
ランドロイド社は2019年4月23日東京地裁に自己破産を申請しました。
【イノベーションについてのまとめ】
イノベーションとは何か、日本企業のイノベーションの例、画期的なアイデアとそれを実現する方法、そしてイノベーターを脅かす模倣者の戦略など、今までのコラムを
「過去のイノベーションとデジタル時代のイノベーションについて」
にまとめました。良かったら、こちらもご参照ください。
本コラムは「未来戦略ワークショップ」のテキストから作成しました。
経営コラム ものづくりの未来と経営
経営コラム「ものづくりの未来と経営」は、技術革新や経営、社会の変革などのテーマを掘り下げ、ニュースからは見えない本質と変化を深堀したコラムです。「未来戦略ワークショップ」のテキストから作成しています。過去のコラムについてはこちらをご参照ください。
以下から登録いただくと経営コラムの更新のメルマガをお送りします。(ご登録いただいたメールアドレスはメルマガ以外には使用しません。)
弊社の書籍

「中小製造業の『原価計算と値上げ交渉への疑問』にすべて答えます!」
原価計算の基礎から、原材料、人件費の上昇の値上げ計算、値上げ交渉についてわかりやすく解説しました。
「中小製造業の『製造原価と見積価格への疑問』にすべて答えます!」
製品別の原価計算や見積金額など製造業の経営者や管理者が感じる「現場のお金」の疑問についてわかりやすく解説した本です。
書籍「中小企業・小規模企業のための個別製造原価の手引書」【基礎編】【実践編】
経営コラム「原価計算と見積の基礎」を書籍化、中小企業が自ら原価を計算する時の手引書として分かりやすく解説しました。
【基礎編】アワーレートや間接費、販管費の計算など原価計算の基本
【実践編】具体的なモデルでロットの違い、多台持ちなど実務で起きる原価の違いや損失を解説
セミナー
アワーレートの計算から人と設備の費用、間接費など原価計算の基本を変わりやすく学ぶセミナーです。人件費・電気代が上昇した場合の値上げ金額もわかります。
オフライン(リアル)またはオンラインで行っています。
詳細・お申し込みはこちらから
月額5,000円で使える原価計算システム「利益まっくす」

中小企業が簡単に使える低価格の原価計算システムです。
利益まっくすの詳細は以下からお願いします。詳しい資料を無料でお送りします。


コメント